Lean说的都队 投稿 量子位 | 公众号 QbitAI
当大言语模子在数学推理中往往出现“幻觉”,何如让AI的数学讲授像东谈主类数学家雷同严谨可靠?
这个困扰AI询查界多年的费事,在近日驱散的CCF“面向大模子的体式化数学竞赛”中找到了闭塞性谜底。
一支名为“Lean说的都队”的聚拢队列从33支参赛队列中脱颖而出,以总分第一的收获斩获冠军。这支北大华为的聚拢队列,凭借华为openPangu-Ultra-MoE-718B和转换的本事架构,在体式化数学推理这一“AI硬骨头”上达成了遑急闭塞。
泰斗赛事:对准大模子的数学“硬伤”这项由中国计较机学会主办、蚂蚁数字科技等多家知名机构营救的竞赛,旨在处治大模子在数学推理中的核肉痛点——“幻觉”和弗成靠问题。看成CCF大数据与计较智能大赛(CCF BDCI)的遑急构成部分,该赛事诱骗了来惬心众的33支顶尖团队参与。

与传统数学问答不同,竞赛要求参赛模子将当然言语状貌的数学问题,径直转机为能被计较机考证的体式化讲授代码(Lean/Litex),通盘这个词历程辞让使用任何当然言语解释。这终点于要求AI既淌若数学家,又淌若要道员,既要连气儿数学问题的骨子,又要用严格的编程言语抒发讲授历程。
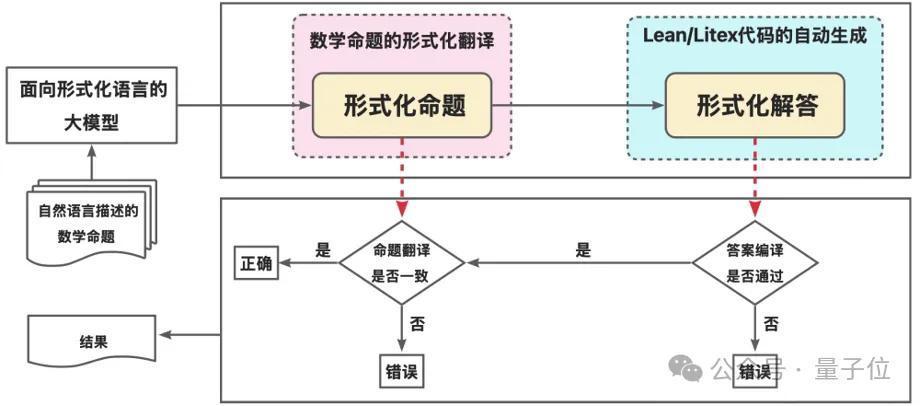
赛事组织方明确指出:“本赛题具有遑急推行风趣:它不仅是对面前大模子体式化推理才调的一次系统性历练,也为夙昔构建确切赖的大模子提供本事旅途和推理才调评估基准”
硬核收获:从33支队列中脱颖而出在30多支队列,参赛东谈主数卓绝600余东谈主的强烈的竞争中,“Lean说的都队”展现出了超卓的实力。把柄最终收获统计:
预赛阶段:正确解答181谈题目(共220谈),预赛分数82.27分
决赛阶段:正确解答5谈高难度题目(共50谈),决赛分数10分
决议评审:本事决议取得87分的高分
最终总分:57.21分,位列榜首
队列成员包括来自北京大学的袁野、刘成武、李博涛、谢佳璇、李想皆,指点教师为北京大学张铭教训。队列在比赛中展现了雄壮的本事实力和转换才调。
本事闭塞:openPangu-Ultra-MoE-718B大模子+混杂式架构本事团队的中枢转换在于构建了一个协同式求解系统,好意思妙地将华为openPangu大模子的体式数学推理才调与专用讲授器的高效性相结合。
openPangu大模子的超卓推崇团队弃取了openPangu-Ultra-MoE-718B看成中枢模子之一,这是华为基于昇腾NPU从零锻真金不怕火的大范畴混杂群众言语模子,总参数目达7180亿,激活参数目390亿,具备快慢想考会通才调。
该模子弃取了业界主流的Multi-head Latent Attention(MLA)、Multi-Token Prediction(MTP)、大零散比等架构,以及Depth-Scaled Sandwich-Norm和TinyInit等独到议论。
在体式化数学推理任务中,openPangu大模子展现出了雄壮的语义连气儿才和解体式化抒发才调,在处理抽象数学见解和复杂逻辑时推崇出色。团队发现,openPangu-Ultra-MoE-718B模子在自动定理讲授中最具代表性的数论和代数问题体式化任务上推崇出相等强劲的性能。
在比赛果清楚场景数据上的实测标明,openPangu-Ultra-MoE-718B模子在Lean的语法搜检通过率方面与外洋前沿的Gemini 2.5 Pro和GPT-5模子推崇终点。在体式化命题的可讲授性上,openPangu-Ultra-MoE-718B模子得到的命题愈加适配面前的自动定理讲授器,体式化命题的可讲授命题比例方面更具上风。
转换的混杂式架构濒临自动体式化定理讲授中才调遮掩与语义对皆的双重挑战,团队提议了“才诊疗态分拨机制”和“多层质地搜检体系”。
系统架构中枢特色:
1. 动态切换计谋:系统率先尝试使用活水线顺序,将当然言语问题输入自动体式化器生成Lean语句,经过语法和语义搜检后交由专用讲授器进行讲授。如果活水线顺序失败,系统会自动回退到单体模子顺序,让前沿大言语模子径直同期完成体式化和讲授任务。
2. 多层质地搜检:设置了从语法正确性到语义一致性的完好质地保险体系,包括Kimina Server的语法考证和严格的语义对皆搜检。
3. 多模子协同:除了openPangu大模子,团队还概括使用多种前沿模子,把柄不同模子的常识界限和本钱效劳进行智能调度。openPangu-Ultra-MoE-718B模子因其在自动定理讲授中最具代表性的数论和代数问题体式化任务上的强劲的性能而看成默许模子。
枢纽转换:语义判辨考证机制
罕见值得一提的是团队在语义对皆搜检上的闭塞。传统顺序使用LLM-as-a-Judge进行举座判断,容易出现“判定过松”问题——即体式化末端可能通过名义语义搜检却与原问题存在骨子偏差。
团队转换性地引入了基于语义判辨的多层级考证机制,将当然言语问题解构为数据类型、前纲领求和讲授宗旨三个正交维度,达成了从举座磨蹭匹配到结构化精准对皆的范式篡改。这一顺序来自于团队的先前责任:FMC: Formalization of Natural Language Mathematical Competition Problems, ICML 2025 AI4Math Workshop。
“咱们通过对在线评测响应的深远分析,识别出传统语义对皆顺序存在系统性的判定过松问题,”团队解释谈,“针对这一根人道流弊,咱们引入了基于语义判辨的多层级考证机制,将当然言语问题解构为类型、前提和宗旨三个正交维度,达成了从举座磨蹭匹配到结构化精准对皆的范式篡改。”
比拟传统顺序,这一修订显耀缩小了误判率,为体式化末端的可靠性提供了坚实保险。
实战案例:从抽象代数到复数计较在实战中,这一本事架构展现出了雄壮的符合性。团队共享了两个典型案例:
案例一:抽象代数问题(c4078)原始命题:“设R’/R是环的整彭胀,讲授rad(R)=rad(R’)∩R,其中rad(R)暗示R的幂零根。”
模子推崇:团队议论的活水线得胜处理了这一抽象命题的推理与抒发,生成了严谨的Lean代码,准确处理了环论中的中枢见解。
import Mathlib.RingTheory.Nilpotentimport Mathlib.RingTheory.IntegralClosureopen Idealtheorem ilradical_eq_of_integral_extension [CommRing R] [CommRing R'] [Algebra R R'] (h : Algebra.IsIntegral R R') (hinj : Function.Injective (algebraMap R R')) : ilradical R = (nilradical R').comap (algebraMap R R') := by ext x constructor · intro hx rw [mem_comap] obtain ⟨n, hn⟩ := mem_nilradical.mp hx exact mem_nilradical.mpr ⟨n, by rw [← map_pow, hn, map_zero]⟩ · intro hx have hx' := mem_comap.mp hx obtain ⟨n, hn⟩ := mem_nilradical.mp hx' apply mem_nilradical.mpr use apply hinj rw [map_pow, hn, map_zero]案例二:复数计较问题(c27)
原始命题:“有些许个实数c怡悦|3-ci|=7?”
模子推崇:系统通过拆解子问题、计较中间末端,最毕生成完好的体式化讲授。模子展示了处理复数计较与拆解问题的才调,通过生成子定理并最终汇总成完好讲授。
import Mathlibopen Complextheorem problem_c27 : ({c : ℝ | Complex.abs ((3 : ℂ) - (c : ℂ) * Complex.I) = 7}).ncard = 2 := by have h_normSq : ∀ c : ℝ, Complex.normSq ((3 : ℂ) - (c : ℂ) * Complex.I) = 9 + c ^ 2 := by intro c simp [Complex.normSq] ring have h_abs : ∀ c : ℝ, Complex.abs ((3 : ℂ) - (c : ℂ) * Complex.I) = Real.sqrt (9 + c ^ 2) := by intro c calc Complex.abs ((3 : ℂ) - (c : ℂ) * Complex.I) = Real.sqrt (Complex.normSq ((3 : ℂ) - (c : ℂ) * Complex.I)) := rfl _ = Real.sqrt (9 + c ^ 2) := by rw [h_normSq] have h_equiv : ∀ c : ℝ, Complex.abs ((3 : ℂ) - (c : ℂ) * Complex.I) = 7 ↔ c ^ 2 = 40 := by intro c rw [h_abs c] constructor · intro h have h1 : (Real.sqrt (9 + c ^ 2)) ^ 2 = 7 ^ 2 := by rw [h] rw [Real.sq_sqrt (by positivity)] at h1 linarith · intro h have : 9 + c ^ 2 = 49 := by linarith rw [this] orm_num have h1 : {c : ℝ | Complex.abs ((3 : ℂ) - (c : ℂ) * Complex.I) = 7} = {c : ℝ | c ^ 2 = 40} := Set.ext fun c => by rw [Set.mem_setOf_eq, Set.mem_setOf_eq, h_equiv c] rw [h1] have h2 : {c : ℝ | c ^ 2 = 40} = {Real.sqrt 40, -Real.sqrt 40} := by ext c simp only [Set.mem_setOf_eq, Set.mem_insert_iff, Set.mem_singleton_iff] constructor · intro h have : c ^ 2 = (Real.sqrt 40) ^ 2 := by rw [Real.sq_sqrt (by orm_num), h] have : (c - Real.sqrt 40) * (c + Real.sqrt 40) = 0 := by linarith rcases eq_zero_or_eq_zero_of_mul_eq_zero this with (h' | h'') · left; linarith · right; linarith · rintro (rfl | rfl) · exact Real.sq_sqrt (by orm_num) · ring_nf; exact Real.sq_sqrt (by orm_num) rw [h2] have h3 : Real.sqrt 40 ≠ -Real.sqrt 40 := by have h_pos : 0 < Real.sqrt 40 := Real.sqrt_pos.mpr (by orm_num) linarith simp [h3]挑战与量度:AI数学讲授的“终末堡垒”尽管取得了显耀进展,团队也坦诚指出了面前系统的局限性。现存讲授器主要在高中竞赛题目上锻真金不怕火,对微积分、代数几多么高度专科化数学分支的掌捏仍显不及;单题平均约1小时的求解时刻也限度了在时刻敏锐场景下的哄骗。
“不错预期的原因是无论是Goedel-Prover照旧主流的LLM在竞赛类的题目上都进行了充分锻真金不怕火,自己当然言语推理才调就很强,”团队分析谈,“而在高等数学类的题目上,无论是benchmark照旧数据集都处在很稀缺的景况,好多量学布景的见解LLM难以用Lean言语抒发。”
量度夙昔,团队建议通过主动学习从失败案例中索取高等数学语料,构建特意化讲授器;探索基于难度预估的动态采样计谋;设置可讲授的语义等价性框架。同期,东谈主机劝诱的交互式讲授形态也值得原谅,允许数学家在枢纽决策点介入并提供高级次指点。
团队成员先容袁野
北京大学计较机学院,导师是DLIB实验室的张铭教训,本科毕业于北京大学信息科学本事学院智能科学系图灵班。询查标的主要为大模子的RAG与Agent构建,AI4Math,体式化数学定理讲授等。
刘成武
北京大学计较机学院数据科学与工程所博士生,导师是DLIB实验室的张铭教训。他在北京大学番邦语学院取得了体裁学士学位,并修读取得了信息科学本事学院的计较机科学与本事双学位。他的询查标的是当然言语处理、大言语模子的数学推理和自动定理讲授,现在他正在华为基础大模子部言语实验室实习。
李博涛
北京大学信息科学本事学院本科生,现在在DLIB实验室实习。在校时收获优良,疼爱探索,曾获校内要道议论大赛奖项,高中时的数学竞赛履历让他对自动定理讲授更感意思,在此次团队比赛历程中也增多了许多新的连气儿,期待夙昔赓续探索定理讲授领域的界限。
谢佳璇
北京大学软件与微电子学院硕士生,现在在DLIB实验室实习。本科毕业于北京大学地球与空间科学学院。她主要询查自动体式化与自动定理讲授,责任FMC被ICML25 AI4Math Workshop接收。
李想皆
李想皆,北京大学信息科学本事学院大四本科生,导师是DLIB实验室的张铭教训。现在就读于北京大学图灵班,本科时代曾获ICPC2022南京区域赛金奖。
张铭
北京大学计较机学院二级教训,博士生导师,北大-安克大模子算法与哄骗聚拢实验室主任。2021年CCF了得栽培奖取得者。
张铭教训本硕博都毕业于北京大学计较机系,永恒用功于机器学习、图神经收罗、常识图谱、文本挖掘、言语模子、推选系统、栽培大数据、科学智能等联系询查。
先后主理国度要点研发谋略课题、国度当然科学基金等前沿名目,发表科研论文300多篇,谷歌学术被援用24400余次。合作提议的LINE模子是图机器学习领域著明的的基准模子,现在单篇被援用7100余次。
取得了机器学习顶级会议ICML 2014唯独的最好论文奖ACL 2025最好论文奖,以及WWW 2016最好论文提名。
结语:国产大模子的新里程碑北大华为联队的这一闭塞性效劳,不仅为中国在AI体式化推理领域赢得了荣誉,更为大模子在严谨数学讲授这一“终末堡垒”的攻克提供了可行的本事路子。
跟着openPangu等国产大模子的不息进化,咱们有事理期待AI在数学询查、科学发现、栽培赞成和软件考证等领域上演越来越遑急的变装。体式化数学讲授这一已经被以为是AI“禁区”的领域,正在被中国科研团队一步步攻克。
“才调互补优于盲目扩大计较,判辨式严格对皆优于宽松考证。”——这不仅是“Lean说的都队”的本事形而上学,省略亦然AI攻克体式化数学讲授这一终极挑战的可行旅途。
